|
Amodal completion in visual perception
Slobodan Markovich
Key words: vision,
perception, representation, cognition, amodal completion, ecological, neural,
connectionist, occlusion
This paper is concerned with the problem of amodal completion
in visual perception. In the first part the basic concepts and theoretical
approaches towards the vision are exposed. In the second part the phenomenon
of amodal completion is described.
1. Vision 1.1. Vision and the other senses According to one of the widely accepted classification the senses can be grouped in two major classes, propriception and exteroception. Proprioception gives us information about ourselves, that is, about position and motion of our body (sense of orientation or vestibular sense), position and movement of our limbs (kinesthesis, i.e. sensitivity of muscles and joints) and states inside our body (visceroception, inner pain and the like). Exteroceptive senses collect and provide information about the external world, such as spatial arrangements of objects and the events in environment. The two subgroups of exteroceptive sense can be identified, contact and distant. Direct mechanical contact with the object is required in contact senses, such as taste and haptic system. For instance, in haptic perception object is grasped and explored (haptic = active touch = skin sensitivity + kinesthesis). Distant sensory organs are not in close mechanical contact with the sources of external stimuli They receive the effects of distant objects, such as emitted chemical molecules in the case of olfaction (sense of smell), sounds produced by distant source in the case of audition (sense of hearing) and the light reflected from the surfaces of objects in the case of vision (sense of seeing). Comparing to other exteroceptive senses, vision is dominant sensory system for man. For instance, olfactory sensory tractus is consisted of less than 10 000 fibers, auditory nerve includes about 25 000 fibers, whereas the optic nerve has almost 1 000 000 neural fibers. The importance of vision in humans (and in other primates, as well) can be deduced from the fact that the large space in cerebral cortex is devoted to vision. More than one third of all cortex is included in processing and elaboration of visual information: primary and secondary areas in occipital region, higher visual zones in inferotemporal and parietal lobes, associative centers in frontal lobe and many diffuse regia in non-dominant (mainly right) cerebral hemisphere. However, there are species in which vision is not dominant sense. For instance, insectivores, rodents and other nocturnal and subterranean mammals (i.e. animals that live in low light conditions), primarily are oriented towards analysis of olfactory and auditory information. Some of these creatures are almost or entirely blind, but they have very good exteroceptive acquisitions. The extreme example is the bat with its echo-location system. In one completely different ecological environment, such as water, live the animals with similar location acquisitions (e. g. sonar in dolphins). Whales, dolphins and some other aquatic mammals, have considerably reduced visual system (water is poor medium for vision due to the great light absorption), but they developed very sensitive auditory systems which enable long distance communication (few hundred kilometers in whales). Visual description of external world is more precise, reliable and comprehensive than any other sensory description. Wales can hear their friends at the 100 km, but we can see the stars which are much more distant. Active touch provides the information about the texture, size and shape of grasped object, but not of color, shadows and complex spatial distribution of objects. Vision is prevailing sense when it is put in conflict with other sensory modalities. For example, when we watch the movie, we usually "hear" that the actors voice comes from its mouth and follow his motion, instead it comes from the stationary loud-speaker. More than any other sense, vision gives us the basis for the representation of space and helps us to understand the complex spatial relationships. The geometry is intrinsically visual (for us, humans, it is not easy to imagine olfactory or auditory geometry), the concept of multidimensionality in physics is quite clear up to the three-dimensional space + time (visual constrains: 3-D space + motion) etc. Relation vision-conception is closely connected with the
question what are the similarities and differences between the perceptual
detection of concrete objects and the representation of abstract features
and relations. In the next paragraph this problem will be considered more
detailed.
1.2. Vision and language Besides that the man is a visual animal, he is also a talking animal. These two capabilities, to see and to speak, are different in many elements. They are different in format of information packing and information processing. The visual information is given spatially, analogously and holistically (spatial field topology preserved) and processed parallel and immediately (all at once). Linguistic (verbal) information is temporal, digital and discrete, and it is processed serially and subsequently (sign by sign). Visual information processing is automatic and natural (non-intelligent), whereas the linguistic information processing requires intelligence. Intelligence is necessary for language acquisition. Without intelligence we could not understand the meaning of words and use syntax rules (how to organize the words into the meaningful messages). In addition, language in its both variant, spoken and written, has strong social, cultural and historical dimension. Thanks to its inner structure the language is highly economic, flexible and productive (few tens of basic phonemes + combinatory rules = infinite number of messages). In this case, vision is less productive and flexible because it is constrained by concrete object distribution. However, vision (or visual description) of particular object is more economic and more precise than the verbal description of same object. We will much easier and more correctly know how exactly look particular animal, machine or picture if we simply look at them, than if we use even highly scrutinized and detailed verbal description. Vision and language have complementary functions: vision is oriented towards the description of external world, while, the language and speech are means for communication and articulation of thoughts. This division of labor is biologically profitable because it enable the separation of attention on two different sensory realms. In the same time we can speak with another person and to watch the environment or to follow some other activities. Such division of attention would be prevented if we would forced to communicate to each other by gestures (like deaf persons). In that case we could concentrate only to one job communication. Vision and language are not completely distinct. They are overlapping so that there are some linguistic elements in vision and visual elements in language. Linguistic, i.e. symbolic elements in vision can be noticed in the following phenomena: visual signs and visual communication (e. g. language of deaf persons, traffic signs etc.), visual intelligence (e. g. many tests of intelligence include visual perception tasks), visual thinking and imagination (e. g. spatial concepts, visualization of objects etc.), symbolism of dreams etc. Sequentionality of vision can be found in two groups of phenomena, eye movements and information processing within visual system. Records of eye movements show that the image of objects is constructed part by part (fixation point of eyes practically jumps across the surface of object). Modern visual science shows that visual perception of object has temporal dimension. The retinal image (retinal image = mosaic of excitation of photoreceptors in eye) is processed holistically and parallel, but it passes through several stages within visual system (parallel processing + sequentional elaboration) So, during the given period of time the perceptual image of external objects becomes more and more articulated, precise and rich. Visual elements in language can be noticed in wide spectrum
of phenomena such as figural (metaphorical, poetic) language and pictorial
writings (including calligraphy). Studies of eye movements in reading process
show that single words are read as wholes (not letter by letter). Although
these phenomena ask for extensive elaboration, we will go back to the problem
of vision. Now, the levels of visual symbolization will be described.
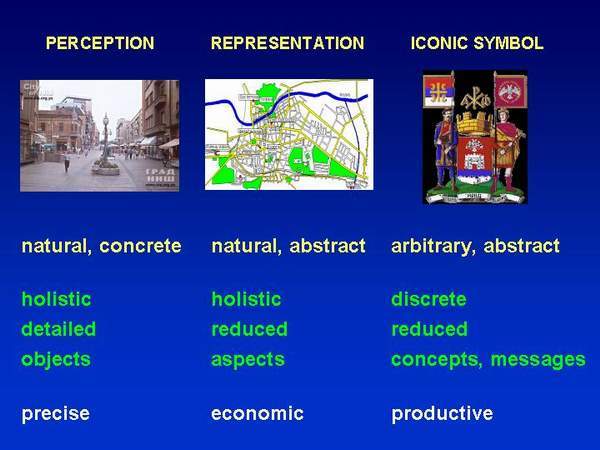
1.3. Visual symbolization The levels of symbolization will be defined through the levels of abstraction (some features extracted, others reduced) and arbitrarity (sign designated). The lowest level of symbolization is perception. It is not symbolization in the full sense because percept is concrete (nothing is extracted/reduced) and natural (non-arbitrary). In addition, perception is holistic, object oriented and it offers a detailed description of objects and events. The next level of symbolization is representation. Visual representations such as geographical and architectonic maps, sketches, geometrical projections, linear perspective drawings etc. are abstract and natural. They are abstract because they extract particular aspects of world (e. g. distribution of subway stations and traces) and they are natural (non-arbitrary) because they preserve topology of external world. Representations are holistic (like perception), but they are reduced in details and oriented toward particular aspects of world. Besides the representations of physical world (e. g. maps and plans), there are the representations of mental states (e. g. abstract expressionism picture represents particular emotional state). Finally, the highest level of visual symbolization includes the iconic signs, such as gesture language, traffic signs, heraldic signs, logotypes etc. Iconic signs are abstract and arbitrary (e. g. there is nothing intrinsically common to swastika and fascism or red star and communism). Iconic signs are discrete (e. g. gesture language), reduced in details and oriented toward denotation of complex concepts (e. g. coat of arms denotes the state) or messages (e. g. traffic sign which "says": "the road gets narrower here ").
Figure 1: Three levels of visual symbolization. Each of the above-mentioned levels implies corresponding
neural and mental capabilities (perception, memory, imagination, cognition).
However, some theories make confusion between perception and cognition,
so, we can find the pan-cognitive concepts such as perceptual intelligence
(or understanding of sensory signs) and pan-perceptual concepts such as
seeing the problem (or insight).
1.4. Visual perception and visual cognition All visual phenomena can be classified in two large groups,
visual perception and visual cognition. Visual perception is detection
of present scenes, objects and events (it will be elaborated later in more
details). Visual cognition is mental manipulation ("mentipulation") of
absent contents. It encompasses the different processes and capabilities.
Imagery or visualization, that is, creating mental images or mental representations
of absent or unreal objects and events. Visual memory, that is, storing
and organizing mental representations and filling the missing details.
Visual intelligence, that is, capacity for manipulation of visual contents
(mental rotation, labyrinth test, camouflage tests etc). Visual intuition
and knowledge, that is, understanding the meaning of pictures, iconic symbols
etc. Dreams, that is, symbolic combinations of mental images and creating
the unconscious messages.
1.5. Visual perception: basic concepts Visual perception includes the three domains, physical,
physiological and psychological. Physical domain encompasses the optical
stimulation, that is, the light. Physiological domain encompasses the neural
processing of optical information from eye to higher cortical areas. Finally,
psychological domain refers to the phenomenological state of consciousness
during the watching particular object. Hence, information about the object
is at least twice encoded/decoded. The first encoding is transformation
of light energy into neural impulses, and the second encoding is transition
from neural to conscious level. Ambient light is reflected from the objects
carrying the information about their surface, texture, color (spectral
composition), shape, size, relative position, motion (direction and velocity
of position change), orientation and so on. One of the central question
for vision science is how our visual system processes all that features
and how it binds them again in the coherent, stable and meaningful perceptual
object.
1.6. Neural processing of visual information Visual processing is parallel and sequentional. The visual paths are originating in retina, passing through thalamus (LGN, lateral geniculate nuclei), primary and secondary visual cortex (V1 and V2) and terminating in higher (associative) cortical areas. In different levels of visual system the retinotopic presentation is noticed. Topology of retinal image is preserved in visual cortex, but the central (foveal) portion of this image, is magnified in cortical representation. This cortical magnification is a consequence of the exquisite receptors resolution in fovea and direct (non-convergent) link with receptor and higher order neural cells. Periphery of retina is represented with the smaller space in cortex because it has much poorer resolution. There are several relatively specialized visual paths (for details see Gilbert, 1995; Schiller, Logothetis & Charles 1990; Livingstone & Hubel, 1988; Maunsell, 1993; Merigan & Maunsell, 1993; Ts'o & Roe, 1995; Ungerleider & Mishkin, 1982; van Essen & DeYoe, 1995). From retina via thalamus (LGN) to V1 the two pathways are identified, magnocellular (Magno) and parvocelular (Parvo). Magno pathway originate in periphery of retina. It has a poor resolution, but it is highly sensitive to movement. It is sensitive only to light-dark contrast, not to color. Parvo system has good resolution (it is originating in center of retina) and it includes four spectral sensitive sub paths (cells tuned for red, green, blue and yellow light). In visual cortex the Magno system is transforming into so-called Where pathway (cf. Ungerleider & Mishkin, 1982). This pathway requires binocular inputs and it encompasses depth and motion processing channel (detection of object position and motion in 3-D space). Parvo system is transforming into so-called What pathway (cf. Ungerleider & Mishkin, 1982). This pathway includes the channels for form and color processing (precise identification of object shape, texture and color). The crucial task for visual science is to answer how do
the visual system put all these separately processed information together
into the representation of unique visual world (visual scenes filled with
objects and events). Modern neuroscience of primate visual system indicates
that in higher visual areas the interaction between channels increases.
Neurons in these areas are sensitive to more complex inputs. For instance,
some cells in monkey cortex respond to very complex patterns such as faces:
greatest response to monkey face, somewhat weaker response to human faces,
moderate response to face-like drawings and no response to other objects
(Bruce, Desimone & Gross, 1981).
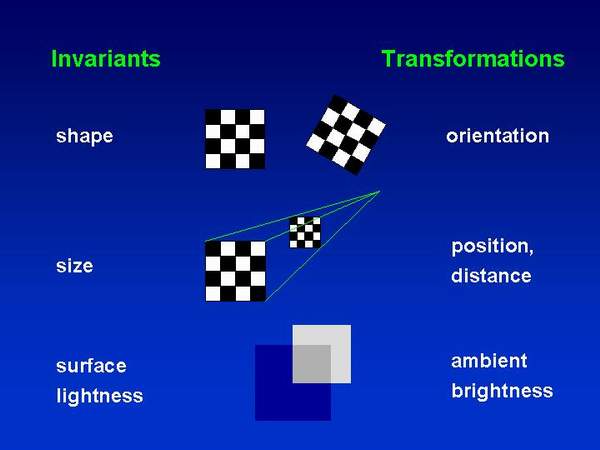
1.7. Perception of invariants and transformations Objects have invariant and variable features. Invariant features are intrinsic properties of objects, such as size, shape and surface lightness/color. Variable features are transformational states of objects, such as orientation, position (distance) and ambient brightness. The transformations physically dont change the intrinsic features: change of orientation doesnt change the shape of object, change of distance doesnt change the object size and change of ambient light doesnt change the surface color.
Figure 2: Invariants and transformations: shape-orientation, size-distance, illumination (shadow)-surface lightness We perceive both, invariant and transformational states of objects. For example, we see that our friend going away from us apparently looks smaller and smaller, but in the same time we see that he doesnt change its size. Similarly we see that the things look darker in the night than during the daylight, but we dont see that they change their natural color. In all that situation we have no problem to extract the invariant (intrinsic) features from the transformations. However, the question is how do we do it when the visual process starts with the non-intelligent retinal image. For example, how does our visual system "knows" whether the received amount of luminance (light reflected from particular surface) is result of low illumination of white surface or of high illumination of black surface! The question is still open, but several theoretical approaches
offer possible solution frameworks. In the next paragraph the three general
approaches to visual perception will be introduced, Ecological, Connectionist
and Cognitivist.
1.8. Theoretical approaches to visual perception. According to famous Gestalt psychologist Kurt Koffka, the central task for perceptual science is to answer the very simple question: Why do things look as they do? (Koffka, 1935) Modern theoretical approaches to perception, ecological, Connectionist and Cognitivist, answer this question starting from very different premises. In his Ecological approach J. J. Gibson (1979) states that the things look as they do because the optical information is what it is. Gibson started from the idea that the structure of ambient light provides all relevant visual information. Environment is informational rich and structured so that organism just need to pick up invariants from large number of transformations. In other words, percept is articulated through the direct interaction organism-environment, not through the neural processing. Gibson actually moved conceptual framework from inside (what is in the head) to outside (where the head is). Connectionist approach of D. Marr (1982) and S. Grossberg (1982) try to find the mathematical description (computational algorithm) of visual information processing. According to Marr, retinal image (primal representation) is filtering in several levels of visual system until it reach complete description of 3-D object (final representation). Thus, visual information passes from more primitive towards more sophisticated and integrated representations. The basic assumptions and concepts for the construction of such neural networks are very simple. So, we have stimulus input, levels of representation, modules in each level, and characteristics of connections between modules: strength, direction, divergence-convergence and excitation-inhibition. In that sense, Marr would say that the things look as they do because their representations are filtered by visual system as they filtered. Cognitivist approach is exposed in theoretical works of I. Rock (1983: Logic of perception), R. Gregory (1972: Intelligent eye) and J. Hochberg (1978). In this approach the perception is defined as interpretation of rough, poor and ambiguous sense data. Perceptual system is forced to solve the problems (a. g. which 3-D object is represented by 2-D retinal image) and to test different hypotheses (e. g. one trapezoid may be frontal-parallel representation of trapezoid, but it can be projection of slanted square, or any other quadrangle). After the consulting the memory (prior experience, knowledge), the perceptual system concludes what solution is most likely. So, the Cognitivists would reply to Koffka that the things look as they do because we learned (i. e. we know) that they look as they do. Although above-mentioned approaches tend to explain the same thing, that is the perception, each of them emphasize particular aspect of perception as more important than others. So, the Ecological approach emphasizes the perception in ecologically natural conditions with active observer and rich environment, The typical subject of interest for this approach is the perceptual-motor coordination and the regulation of sensory and action systems during the manipulation with objects, using the tools, driving the vehicles etc. Connectionist approach is more interested for the extreme perceptual phenomena, such as illusions. For this approach the illusions are good methodological means for study the visual system. They very clear show how do the visual system filter representations in normal conditions. For example, the role of so-called lateral inhibition in neurons system (some neurons reduce the activity of their neighbors) is quite obvious in lightness illusions. However, the same principle is responsible for the sharpen of contours in normal perceptual conditions (the contrast contour-surrounding increases due to lateral inhibition, but we dont see this as illusions).
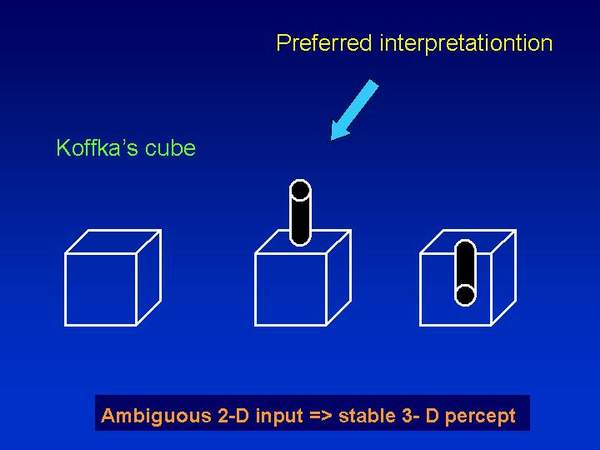
Figure 3: Visual illusions: Zölner illusion (horizontal lines are parallel) and lightness contrast (lightness of rectangle is uniform). Cognitivist approach stresses the ambiguity of retinal image and it hypothesizes the central process of ambiguity reduction. The favorite topics of this approach is perceptual learning, development of perceptual skills, perception of multistable or ambiguous figures, detection of hidden figures end the like.
Figure 4: Ambiguity in visual perception: two perceptual interpretations of Koffkas cube.
2. Amodal completion 2.1. Visual completion: modal and amodal Sometimes we can see something what is not given in optical stimulation. In the case of modal completion, such as filling the blind spot in retina or binding the discrete sets of images in continuous stroboscopic motion, we have strong sensory experience about the completeness (cf. Kanizsa, 1979; Kanizsa & Gerbino, 1982). We doesnt see the gap in our visual field which corresponds with the place of blind spot (place where optical nerve leaves the retina). Looking the movie we doesnt see the snapshots of static images. In other words, the modally completed visual percept is phenomenologically identical with the perception of physically completed objects.
Figure 5: Blind spot: close your left eye and focus the cross with the right eye. Move the head forward-backward and find the position in which the black circle disappears. Circle disappears because its images is projected exactly onto blind spot (area where optic nerve leaves the retina). Blind spot is located on the nasal part of both retinae, so the object has to be on the temporal areas of the optic field if we want to project the image onto blind spot (this is due to the crossing light rays in ocular lens) Hence, for right eye, the object has to be on the right part of visual field (blind spot is on the left side), whereas for the left eye it has to be on the left part of visual field (blind spot is on the right side). Modal completion is the process which takes a place at lowest processing levels (retinal ganglion level). However, there is amodal completion, that is the filling of perceptual entity at the higher cortical levels (cf. Kanizsa, 1979; Kanizsa & Gerbino, 1982). Comparing to modal completion in this case we can be aware of physical incompleteness of stimulation. For instance the collinear set of dots, e. g. ............... is usually seen as dotted line. Here, the line is presented as amodal whole, while the dots are also presented as modal constitute parts. This phenomenological dualism is due to the articulation of amodal wholes in the higher levels of visual processing: the primitive representations are not integrated, on the higher levels they are organized in unique patterns. There are many neurophysiological evidences about the neurons in higher visual areas which are sensitive to amodal contours (cf. von der Heydt & Peterhans, 1989; Gilbert, 1995; Ts'o & Roe, 1995; van Essen & DeYoe, 1995).
Figure 6: Examples of amodal squares.
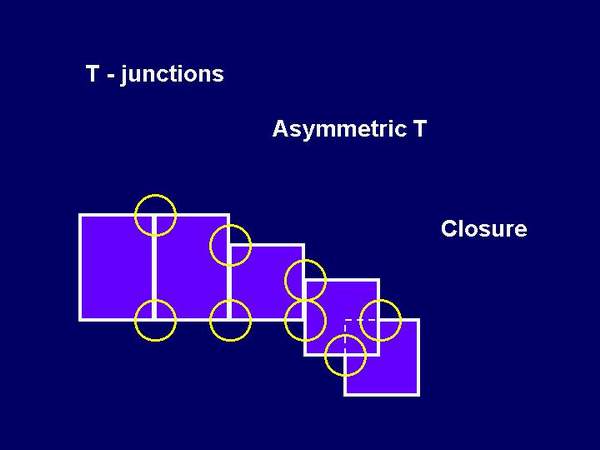
2.2. Visual occlusion Visual occlusion is one of the most frequent amodal completion phenomena. In our everyday life we see many objects which are partly occluded by other objects. However, we dont see the world as a mosaic or a patchwork made of visible parts of objects. It is rather seen as a group of complete objects arranged in depth, so that ones partially overlaps others. This phenomenon implies two questions. The first question is when the mosaic and when the occlusion will be seen. The second question is: if the occlusion is seen what will be seen behind the occluder (what is the complete shape of partly occluded figure). Available experimental data indicates no single factor which determines mosaic vs. occlusion perception. The first factor is so-called T-junction (it is necessary, but not sufficiant), the second factor is asymmetry of T (however, there are asymmetric Ts without occlusion effect), and the third factor is the closure, i.e. contours convergence (cf. Kellman & Shipley, 1991; Boselie & Wouterlood, 1992). See the figure below for explanation.
Figure 7: The factors of mosaic-occlusion perception: T-junction, asymmetric junctions and closure. The next paragraph is concerned with the question what
will be seen behind the occluder.
2.3. General theoretical approaches to visual occlusion. In Figure 8 we clearly see the frontal circle which partly occludes the square. The question is why the invisible part is completed so to attain the shape of a square, and not of some other figure.
Figure 8: Occlusion pattern: the circle partly occludes the square. According to Ecological approach, identification of hidden parts is not a matter of perception. It is rather a matter of cognition (intelligence task or skill to read the pictorial depth cue). In natural perception objects are not given as flat static patterns of lines, but they are dynamic, 3-dimensional and rich in their texture. Much more information about the shape of partly occluded entities is available in moving, 3-D objects than in static 2-D drawings. Cognitivists believe that our perceptual system, facing with wide spectrum of possible completions, prefers the likeliest among them. In other words we will see what is most probable to be seen. The dominance of likely solutions is the consequence of learning process, prior experience, or direct contextual experience (e. g. what sign has to be put on empty space: xxxxx xx). The main point of this approach is that the perceptual process is based on expectations what is the most logical solution: looking at the occlusion patterns we make the conclusions about the most probable shape of partly occluded figure. However, we doesnt choose ever the most logical and most expectable solutions, even sometimes we see the impossible things.
Figure 9: In this scene the enormously an elongated animal is seen, in spite we know that such animal doesnt exist.
Figure 10: Contextual patterns suggest that behind the circle logically must be figure with the shape identical to the shape of the other figures,. However, we tend to complete the partly occluded figure in amodal square.
Figure 11: Contextual patterns suggest that in centar of the pattern logically must be cross-like figure. However, we tend to see this figure as partly occluded square. Connectionist approach starts from the idea that the perception
of occlusion is a consequence of spontaneous distribution of neural network
activities. Being natural self organizing system, a perceptual system tend
to optimize its engagement at most economic level. This idea was included
in classical gestaltistic concept of Prägnanz and minimum-maximum
tendencies in perception (cf. Attneave, 1982; Garner,
1962; Garner & Clement, 1963; Hatfield
& Epstein, 1982; Hochberg & McAlister, 1953;
Koffka, 1935; Köhler, 1920, 1927).
The perceptual tendency towards the processing economy implies the preference
of simplest and most regular solutions. In Figure 8, the square is the
simplest and the most regular solution for the given conditions. However,
regularity and simplicity coincide to each other in the case of square,
but they are not correlated dimensions. So, it is possible to find the
situations when these two organizational principles lead towards different
solutions, the most regular or the simplest. In the next part this situation
is discussed more detailed.
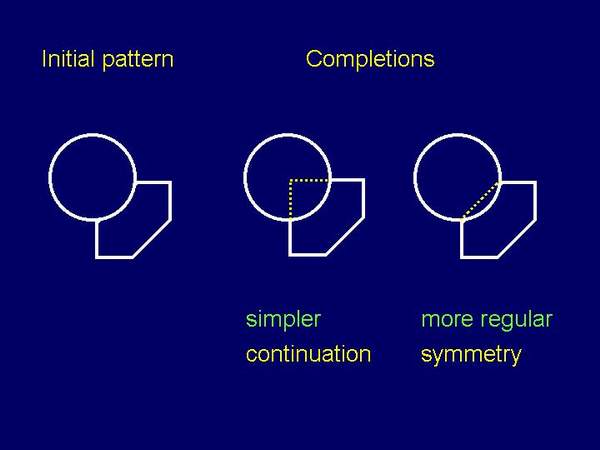
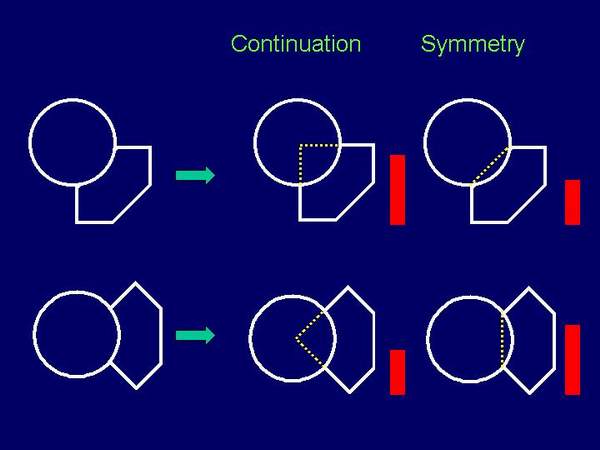
2.4. Global and local strategies of amodal completion in visual occlusion Globally oriented models of completion hypothesize that the perceptual system tends to rich the most regular (symmetric) solutions (cf. Buffart, Leeuwenberg & Restle, 1981; Boselie & Leeuwenberg, 1986; Helm & Leeuwenberg, 1994). This perceptual action is global because the representation of whole figure has to be taken into account in order to articulate the regular figure: visible part + hidden part = globally regular (symmetric) figure. In other words, global models assume that amodal completion takes a place in perceptual instances at very high level (global level, wide scope level).
Figure 12: Two possible completion of the same initial patter: global solution (symmetry prevails) and local solution (good continuation prevails). Locally oriented models start from the idea that amodal completion doesnt require the engagements of very high representational level (cf. Chapanis & McCleary, 1953; Dinnerstein & Wertheimer, 1957; Michote, Thines & Crabbe, 1964; Kanizsa, 1979; Kanizsa & Gerbino, 1982; Rock, 1983; Boselie, 1988; Boselie & Wouterlood, 1989; Kellman & Shipley, 1991; Boselie & Wouterlood, 1992; Wouterlood & Boselie, 1992; Boselie, 1994). During the completion, a perceptual system has a very narrow scope, near to T-junction. The occluded part is completed so that the contours monotonically continue after T-junctions until they connect to each other. In this solution the simplicity is prevailing principle because the contour complexity (change of contour orientation) is minimized. Available data show no prevailing principle which predicts what will be seen behind the occluding figure, i.e. how the perceptual system completes partly occluded figure. Sometimes, the principle of local factors prevails (tendency towards simplest solutions, preference of good continuation), while sometimes the principle of global factors prevails (tendency towards regularity, preference of symmetry). In the next section one of the possible reasons for two-factorial
determination of amodal completion will be considered.
2.5. Effect of contour orientation. Our studies of visual occlusion suggest that the prevailing of local or global factors depends on contour orientation (Markovich, 1998, 1999). The basic idea is that the partly occluded figure is completed so that the contour of occluded part reaches vertical and/or horizontal orientation. Sometimes, this coincides with good continuation principle and this solution is preferred. Sometimes this coincides with symmetry and then this solution is preferred. When we rotate patterns from the positions with vertically/horizontally oriented contours to the position in which the contours get oblique orientation, the completion results are changed (oblique orientation is less preferred).
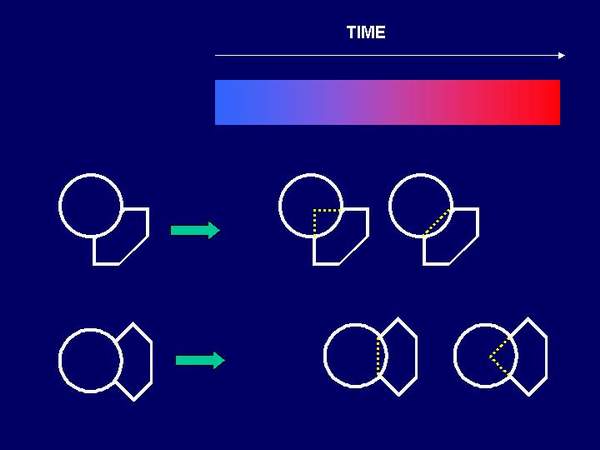
Figure 13: Effect of contour orientation on the preference symmetry vs. good continuation (the higher the column the higher the preference). Amodal completion in visual occlusion has a temporal dimension. Experimental data indicate that this process takes between 100 and 200 milliseconds (for methodological details see Sekuler & Palmer, 1992). In our study the orientational effect of temporal dimension of visual occlusion was noticed (Markovich & Gvozdenovich, 2002). We obtained that the time needed for completion process depends on contour orientation, so that normally (vertically-horizontally) oriented contours are completed faster than the oblique ones.
Figure 14: Schematic presentation of time needed for completion (symmetry vs. continuation) as a function of orientation.
3. Conclusion The phenomenon of amodal completion can be considered as possible link between sensory and cognitive processes because it refers to something that is in the same time a perceptual (we see that one figure partly overlaps other) and imaginative (the look of hidden part is only suggested, not explicitly given). Ecological approach states that the amodal completion is not good paradigm for the study of perception. In natural conditions a perceptual system is not forced to complete anything, but it even selects invariants from the rich informational pool. In the standard experiments with 2-D patterns of contours some extra-perceptual mechanism are prevailing, such as reading the pictorial depth cues. However, the amodal contours are perceptually strong and relatively stable which indicates that it is not correct to classify them in the category of pictorial or iconic signs (see section 1.3. in this article). For Cognitivist approach, the capability for reading the cues (cue = sensory symbol) imply some fundamental intelligence. According to this, amodal completion can be taken as a good example for perceptual hypothesis testing (what is the most likely meaning of ambiguous 2-D sensory data). The pan-logism of this approach is double because it claims that the perception is intrinsically intelligible, and that it is under the strong control of higher cognitive instances (so-called top-down processing). However, this approach fails to explain many cases when the effect of prior experience, knowledge and logic are more than weak. Connectionists are interested to find out how do the visual system works by itself, i. e. irrespectively of memory influences (knowledge reduced), and in the conditions of reduced input complexity. According to this approach, the perceptual system integrates sensory primitives tending to reach the optimal (most economic) solution.However, sometimes is not quite clear what perceptual description is most economic, because in some cases the ambiguous (multistable) primitive patterns can be completed in at least two equally economic ways (e. g. simple and regular outputs). Further studies of amodal completion have to offer a better
insight in all above-mentioned problems, but it has to be stressed that
all studies, previous and future ones, cant be theoretically neutral.
This means that the conceptual value of all obtained experimental data
is always filtered through the framework of either Ecological, Cognitivist
or Connectionist approach.
References Boselie, F. & Leeuwenberg, E. (1986). A test of the minimum principle requires a perceptual coding system. Perception, 15, 331-354. Boselie, F. (1988). Local versus global minima in visual pattern completion. Perception & Psychophysics, 43 (5), 431-445. Boselie, F. & Wouterlood, D. (1989). The minimum principle and visual pattern completion. Psychological Research, 51, 93-101. Boselie, F. (1994). Local and global factors in visual occlusion. Perception, 23, 517-528. Boselie, F. & Wouterlood, D. (1992). A good continuation model of some occlusion phenomena. Psychological Research, 54, 267-277. Bruce, C., Desimone, R. & Gross, C. G. (1981). Visual properties of neurons in a polysensory area in the superior temporal sulcus of the macaque. Journal of Neurophysiology, 46 (1138-1158). Buffart, H., Leeuwenberg, E. & Restle, F. (1981). Coding theory of visual pattern completion. JEP: Human Perception and Performance, 7 (2), 241-274. Chapanis, A. & McCleary, R. A. (1953). Interposition as a cue for the perception of relative distance. The Journal of General Psychology, 48, 113-132. Dinnerstein, D. & Wertheimer, M. (1957). Some determinants of phenomenal overlapping. American Journal of Psychology, 70, 21-37. Garner, W. R. (1962). Uncertainty and structure as psychological concepts. New York: Wiley. Garner, W. R. & Clement, (1963). Goodness of pattern and pattern uncertainty. Journal of Verbal Learning and Verbal Behavior, 2, 446-430. Gibson, J. J. (1979). The ecological approach to visual perception. Boston: Houghton Mifflin. Gilbert, C. D. (1995). Dynamic properties of adult visual cortex. In M. S. Gazzaniga (Ed.), The cognitive neuroscience (pp. 73-90). Cambridge, Massachussets: The MIT Press. Grossberg, S. (1982). Studies of mind and brain: Neural principles of learning, perception, development, cognition and motor control. Boston: Reider Press Hatfield, G. & Epstein, W. (1985). The status of minimum principle in the theoretical analysis of visual perception. Psychological Bulletin, 97 (20), 155-186. Hochberg, J. E. (1978). Perception, Englewood Cliffs, New Jersey: Prentice Hall, Inc. Hochberg, J. E. & McAlister, E. (1953). A quantitative approach to figural "goodness". Journal of Experimental Psychology, 46, 361-364. Kanizsa, G. (1979). Organization in vision. New York: Praeger. Kanizsa, G. & Gerbino, W. (1982). Amodal completion: Seeing or thinking? J. Beck (Ed.), Organization and representation in perception (pp. 167-190). Hillsdale, New Jersey: Lawrence Erlbaum Associates. Koffka, K. (1935). Principles of Gestalt psychology. London: Kegan, Paul, Trench & Trubner. Köhler, W. (1920). Die physische Gestalten in Ruhe und stationären Zustand (Physical Gestalten). U W. D. Ellis (Ed.), A source book of Gestalt psychology, 1938., (pp. 17-70). London: Routledge & Kegan Paul. (Original u Brownschweig: Vieweg & son.) Köhler, W. (1927). Zum Problem der Regulation (On the problem of regulation). M. Henle (Ed.), The selected papers of Wolfgang Köhler, 1971., (pp. 305-326). New York: Liveright. Kellman, P. J., & Shipley, T. F. (1991). A theory of visual interpolation in object perception. Cognitive Psychology, 23, 141-221. Leeuwnberg, E. (1971). A perceptual coding language for visual and auditory patterns. American Journal of Psychology, 84, 307-349. Livingstone, M. S. & Hubel, D. H. (1988). Segregation of form, color, movement and depth: Anatomy, physiology and perception. Science, 240 (740-749) Markovich, S. (1998). Figural completion in occlusion phenomena: effect of contour orientation. Perception (supplement) vol. 26, ECVP '97 Abstracts (98). Markovich, S. (1999). Amodalno kompletiranje delimicno zaklonjenih figura (Amodal completion of partly occluded figures). Psiholoska istrazivanja, 10, 117-145. Marr, D. (1982). Vision. San Francisco: W. H. Freeman. Maunsell, J. H. R. (1992). Functional visual streams. Current Opinion in Neurobiology, 2, 506-510. Merigan, W. H. & Maunsell, J. H. R. (1993). How parallel are the primate visual pathways? Annual Review of Neuroscience, 16, 369-402. Rock, I. (1983). Logic of Perception. Cambridge, Masachusetts: The MIT Press. Schiller, P. H., Logothetis, N. K. & Charles, E. R. (1990). Functions of the colour-opponent and broad-band channels of the visual system. Nature, 205, 204-206. Sekuler, A. B. & Palmer, S. E. (1992). Perception of partly occluded objects: A microgenetic analysis. Journal of Experimental Psychology: General, 121, 95-111. Tso, D. Y. & Roe, A. W. (1995). Functional compartments in visual cortex: segregation and interaction. In M. S. Gazzaniga (Ed.), The cognitive neuroscience (pp. 325-337). Cambridge, Massachussets: The MIT Press. Ungerleider, L. G. & Mishkin, M. (1982). Two cortical visual szstems. In D. G. Ingle, M. A. Goodale & R. J. Q. Mansfield (Eds.) Analysis of visual behavior (pp. 549-586). Cambridge, Massachussets: MIT Press. Van Essen, D. C. & E. A. DeYoe (1995). Concurrent procesing in the primate visual cortex. In M. S. Gazzaniga (Ed.), The cognitive neuroscience (pp. 383-400). Cambridge, Massachussets: The MIT Press. van Leeuwen, C. (1990). Perceptual-learning systems as conservative structures: Is economy an attractor? Psychological Research, 52, 145-152. van Lier, R., van der Helm, P. & Leeuwenberg, E. (1994). Integrating global and local aspects of visual occlusion. Perception, 23, 883-903. van Leeuwn, C. & van den Hof, M. (1991). What has happened to Prägnanz? Coding, stability or resonance. Perception & Psychophysics, 50 (5), 435-448. von der Heydt, R. & Peterhans, E. (1989). Mechanisms of contour perception in monkey visual cortex: I. lines of pattern discontinuity. Journal of Neuroscience, 9, 1731-1748. Wouterlood, D. & Boselie, F. (1992). A critical discussion of Kellman and Shipley's (1991) theory of occlusion phenomena. Psychological Research, 54, 278-285. |